or
or  ?
?ABSTRACT
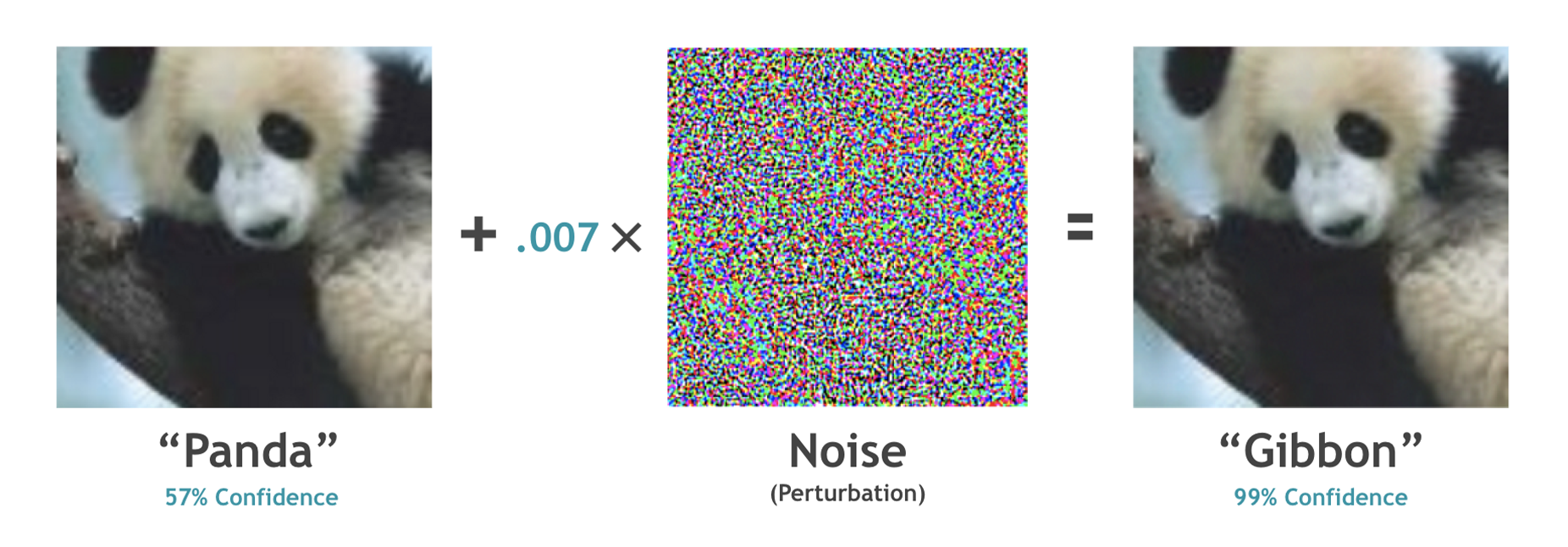
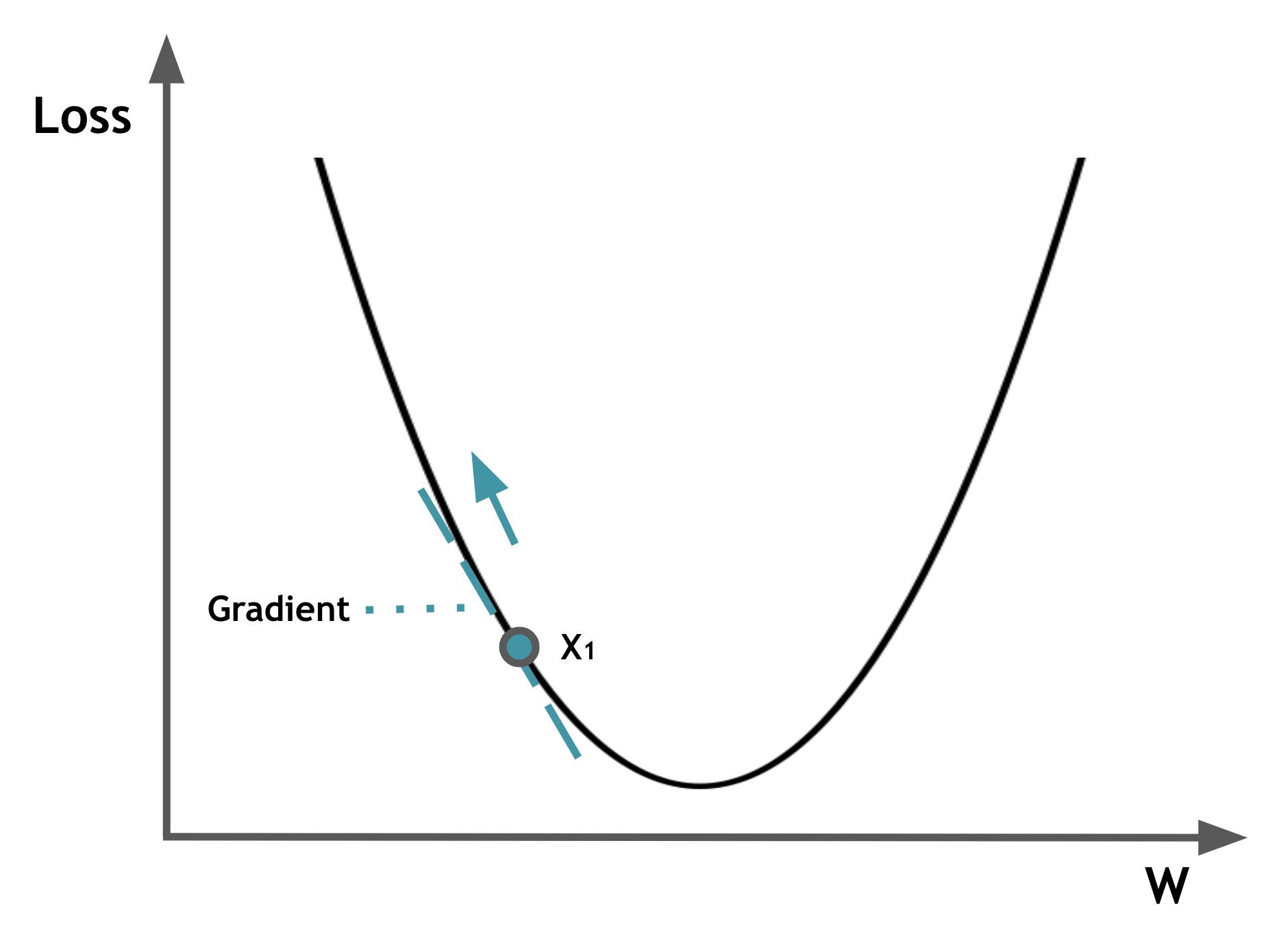
Though deep learning models have achieved remarkable success in diverse domains (e.g., facial recognition, autonomous driving), these models have been proven to be quite brittle to perturbations around the input data. Adversarial machine learning (AML) studies attacks that can fool machine learning models into generating incorrect outcomes as well as the defenses against worst-case attacks to strengthen model robustness. Specifically, for image classification, it is challenging to understand adversarial attacks due to their use of subtle perturbations that are not human-interpretable, as well as the variability of attack impacts influenced by attack methods, instance differences, or model architectures. This guide will utilize interactive visualizations to provide a non-expert introduction to adversarial attacks, and visualize the impact of FGSM attacks on two different ResNet-34 models. We designed this guide for beginners who are familiar with basic machine learning but new to advanced AML topics like adversarial attacks.